My research takes the position that listeners are sensitive to patterns of covariation in speech —that knowing these subtle patterns is part of what it means to truly know a language.

Which is great because if people sound the way we expect them to, we're able to understand them better (McGowan, 2015; 2012 LSA presentation)
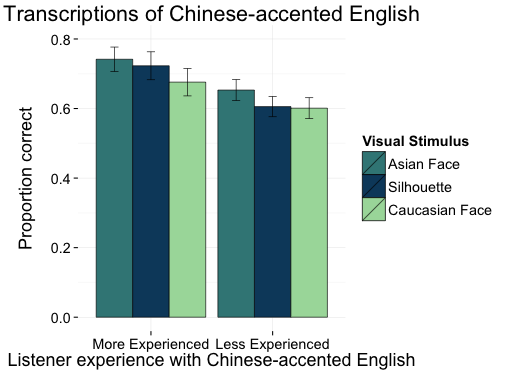



even if our expectations are based on stereotypes rather than authentic experience (McGowan, in press).
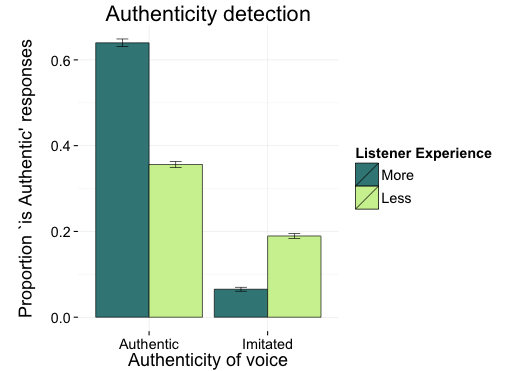
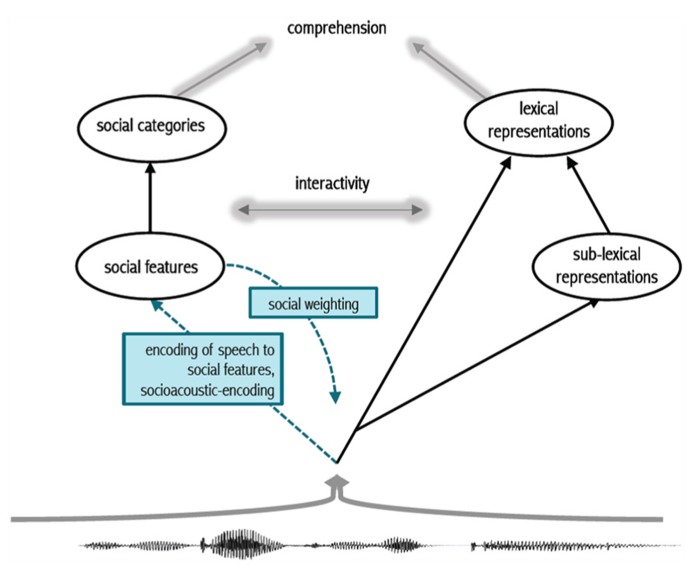
So does all this knowledge and sensitivity only apply to social variation?
First, some quick background on how sounds like [p], [t], and [k] differ from sounds like [b], [d], and [g] at the beginning of English words like pit and bit. What word is this native American English speaker saying?
![spectrograms of [pɪt] and [bɪt]](images/pit-bit.png) The image to the left is a spectrogram (frequency analysis over time) of the word pit. Hear the puff of air at the beginning? It is highlighted in blue in the spectrogram.
pit and bit both start with the lips completely closed. One of the main differences between them is the duration of the puff of air, this duration is called VOT (voice onset time).
The image to the left is a spectrogram (frequency analysis over time) of the word pit. Hear the puff of air at the beginning? It is highlighted in blue in the spectrogram.
pit and bit both start with the lips completely closed. One of the main differences between them is the duration of the puff of air, this duration is called VOT (voice onset time).
[pʰɪt]
[bɪt]
At least in American English, that puff of air is so important that cutting it out of pit (that first sound you played) results in a word that sounds a lot like bit —though probably with a funny [b], and that funniness is every bit as interesting and important as the change from [p] to [b]!
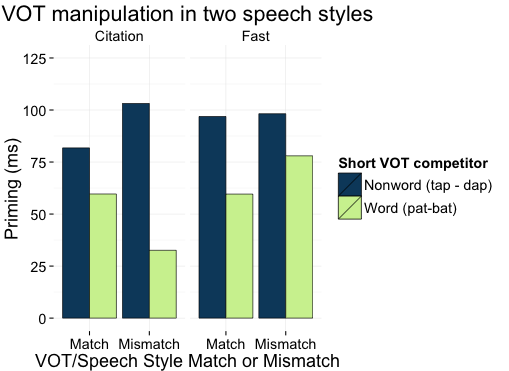
In fact, removing most of the VOT from [p], [t], and [k] words makes them less useful to listeners (shortest green bar) in slow (Citation) speech, but if the rest of the word is spoken quickly the short VOT sounds fine (Fast speech, on the right) (abstract).
Another covarying feature is the way vowels before nasal consonants in English tend to be nasalized. Listeners can use this as soon as it becomes available, not only a large distinction like bend/bed...
but also a much more subtle distinction like the difference in nasalization between these two sound files. Can you hear a difference?
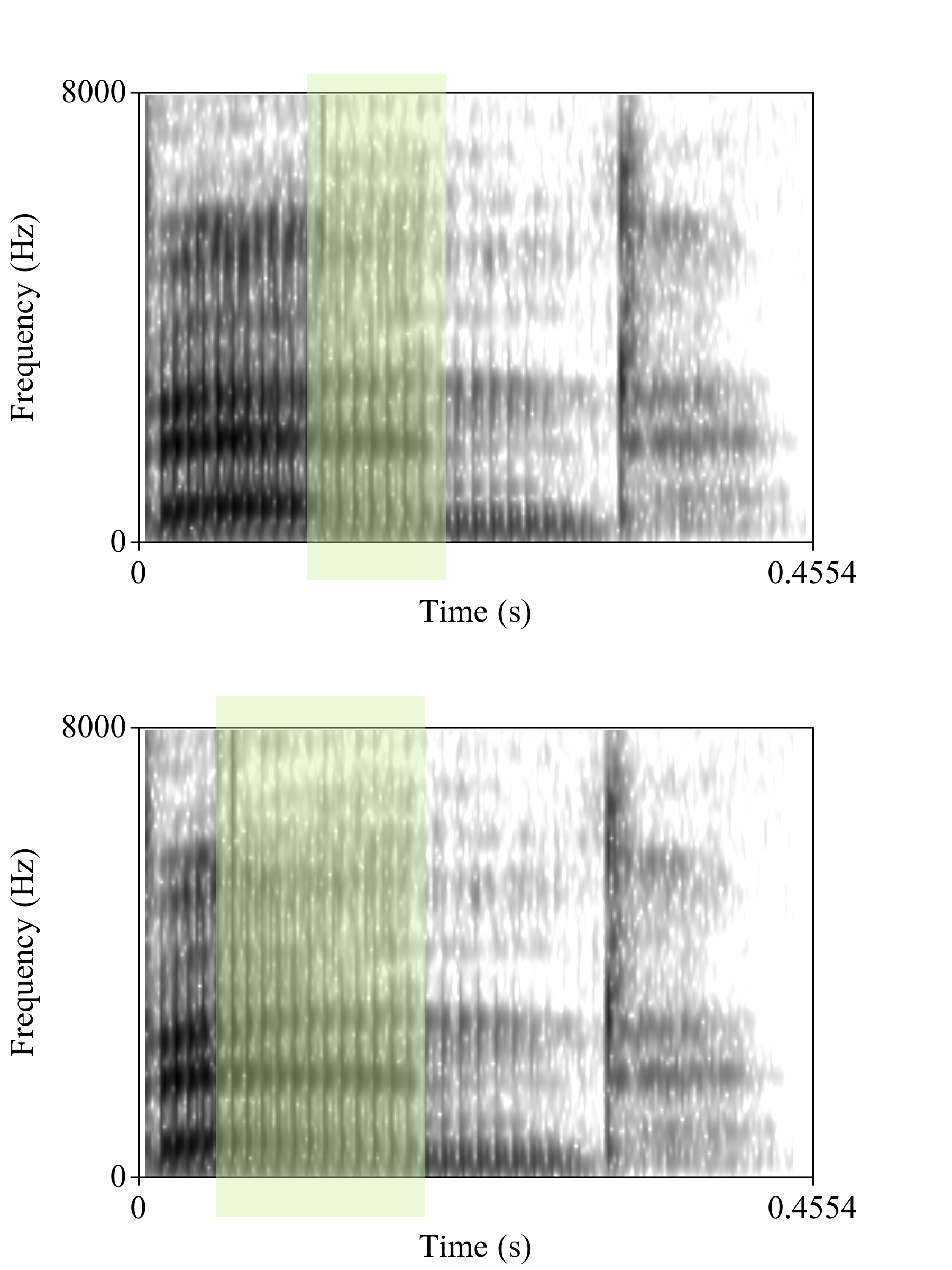 This first recording has late nasalization starting 100 miliseconds after the [b].
This second recording has early nasalization starting 33 miliseconds after the [b].
This first recording has late nasalization starting 100 miliseconds after the [b].
This second recording has early nasalization starting 33 miliseconds after the [b].
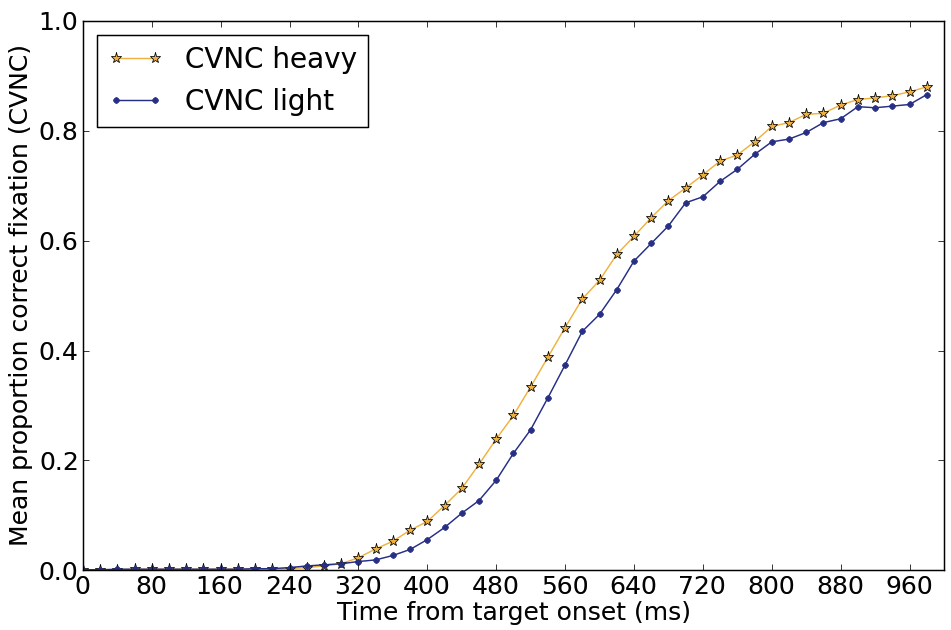
In an eye tracking task we found that listeners can use nasalization as soon as it is present. Looks to the heavily-nasalized word were, on average, 60 ms faster —the same average difference between early and late nasalization in the recordings (Beddor, McGowan, Boland, Coetzee, and Brasher, 2013).
Whether the information is social, contextual, articulatory, or idiosyncratic, we humans have an astonishing ability to attend to it, remember it, and activate it during perception. This ability, my research suggests, is not irrelevant to linguistic competence or even peripheral to it, it is fundamentally and centrally part of what it means to know and speak a human language.
 Thank you for reading! If you have any questions, please contact me via e-mail, twitter, or carrier pigeon.
Thank you for reading! If you have any questions, please contact me via e-mail, twitter, or carrier pigeon.
And many, many thanks to my friend M.C. Nee for turning me into this cartoon.
Publications
@article{McGowan2015a,
author = {McGowan, Kevin B.},
title = {Social Expectation Improves Speech Perception in Noise},
year = {2015},
doi = {10.1177/0023830914565191},
abstract ={Listeners' use of social information during speech
perception was investigated by measuring transcription
accuracy of Chinese-accented speech in noise while listeners
were presented with a congruent Chinese face, an incongruent
Caucasian face, or an uninformative silhouette. When listeners
were presented with a Chinese face they transcribed more
accurately than when presented with the Caucasian face.
This difference existed both for listeners with a relatively
high level of experience and for listeners with a relatively
low level of experience with Chinese-accented English.
Overall, these results are inconsistent with a model of
social speech perception in which listener bias reduces
attendance to the acoustic signal. These results are generally
consistent with exemplar models of socially indexed speech
perception predicting that activation of a social category
will raise base activation levels of socially appropriate
episodic traces, but the similar performance of more and
less experienced listeners suggests the need for a more
nuanced view with a role for both detailed experience and
listener stereotypes.},
URL = {http://las.sagepub.com/content/early/2015/02/03/0023830914565191.abstract},
journal = {Language and Speech}
}
@article{SumnerKimKingMcGowan2014,
author={Sumner, Meghan and Kim, Seung Kyung and King, Ed and McGowan, Kevin B.},
title={The socially-weighted encoding of spoken words: A dual-route approach to speech perception},
journal={Frontiers in Psychology},
volume={4},
year={2014},
number={1015},
url={http://www.frontiersin.org/language_sciences/10.3389/fpsyg.2013.01015/abstract},
doi={10.3389/fpsyg.2013.01015},
issn={1664-1078},
abstract={Spoken words are highly variable. A single word may
never be uttered the same way twice. As listeners, we
regularly encounter speakers of different ages, genders,
and accents, increasing the amount of variation we face.
How listeners understand spoken words as quickly and adeptly
as they do despite this variation remains an issue central
to linguistic theory. We propose that learned acoustic
patterns are mapped simultaneously to linguistic representations
and to social representations. In doing so, we illuminate
a paradox that results in the literature from, we argue,
the focus on representations and the peripheral treatment
of word-level phonetic variation. We consider phonetic
variation more fully and highlight a growing body of work
that is problematic for current theory: words with different
pronunciation variants are recognized equally well in
immediate processing tasks, while an atypical, infrequent,
but socially idealized form is remembered better in the
long-term. We suggest that the perception of spoken words
is socially weighted, resulting in sparse, but high-resolution
clusters of socially idealized episodes that are robust in
immediate processing and are more strongly encoded, predicting
memory inequality. Our proposal includes a dual-route
approach to speech perception in which listeners map acoustic
patterns in speech to linguistic and social representations
in tandem. This approach makes novel predictions about the
extraction of information from the speech signal, and
provides a framework with which we can ask new questions.
We propose that language comprehension, broadly, results
from the integration of both linguistic and social information.}
}
@article{BeddorEtAl2013,
author = "Beddor, Patrice Speeter and McGowan, Kevin B. and Boland, Julie E. and Coetzee, Andries W. and Brasher, Anthony",
title = "The time course of perception of coarticulation",
journal = "The Journal of the Acoustical Society of America",
year = "2013",
volume = "133",
number = "4",
pages = "2350-2366",
url = "http://scitation.aip.org/content/asa/journal/jasa/133/4/10.1121/1.4794366",
doi = "http://dx.doi.org/10.1121/1.4794366",
abstract = {The perception of coarticulated speech as it unfolds
over time was investigated by monitoring eye movements of
participants as they listened to words with oral vowels or
with late or early onset of anticipatory vowel nasalization.
When listeners heard [CṼNC] and had visual choices of
images of CVNC (e.g., send) and CVC (said) words, they
fixated more quickly and more often on the CVNC image when
onset of nasalization began early in the vowel compared to
when the coarticulatory information occurred later. Moreover,
when a standard eye movement programming delay is factored
in, fixations on the CVNC image began to occur before
listeners heard the nasal consonant. Listeners' attention
to coarticulatory cues for velum lowering was selective in
two respects: (a) listeners assigned greater perceptual
weight to coarticulatory information in phonetic contexts
in which [Ṽ] but not N is an especially robust property,
and (b) individual listeners differed in their perceptual
weights. Overall, the time course of perception of velum
lowering in American English indicates that the dynamics
of perception parallel the dynamics of the gestural information
encoded in the acoustic signal. In real-time processing,
listeners closely track unfolding coarticulatory information
in ways that speed lexical activation.}
}
@inproceedings{McGowan2012,
author = {McGowan, Kevin B.},
year = {2012},
title={Gradient Lexical Reflexes of the Syllable Contact Law},
booktitle={Proceedings of the Annual Meeting of the Chicago Linguistics Society 45},
editor = {Bochnak, R. and Nicola, N. and Klecha, P. and Urban, J. and Lemieux, A. and Weaver, C.},
pages={445--454},
organization = {Chicago Linguistics Society},
address = {Chicago}
abstract = {The Syllable Contact Law (SCL) predicts a gradient
preference for syllable contact pairs in a language. However,
this law is most often implemented with strictly categorical
constraints. In this paper I argue that the gradience
underlying the SCL operates synchronically in the grammar
of a language. I examine CELEX corpus data for evidence
of gradient lexical reflexes of the SCL in British English
using pointwise mutual information (PMI). The evidence
appears to support a gradient hypothesis and to be inconsistent
with a strictly categorical model.}
}